
Using AI to Turn Climate Funding Data into Publishable Webpages
In Brief
From Manual Grant Hunting to Intelligent Automation
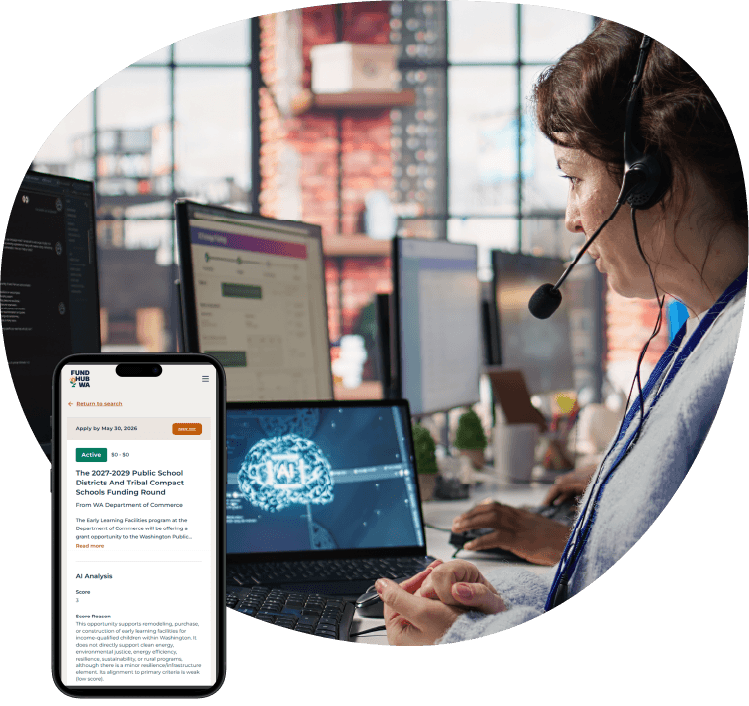
AI agents can help increase service levels and quality by automating manual tasks, freeing people to do work that requires more human judgement. For FundHubWA, that meant changing how funding opportunities were sourced, processed, and published. FundHubWA’s platform connects Washington residents, businesses, and agencies with climate and green energy funding opportunities, but posting grants and incentives took hours of manual work each week burdening limited staff.
To address this challenge, Resource Data built an AI-powered funding aggregator powered by Azure Persistent Agents. It takes on the heavy lifting of pulling in, structuring, scoring, and drafting the listings for funding opportunities based on FundHubWA’s criteria. This shifted the team’s focus from manual work to decision-making, sped up publishing, and enabled FundHubWA to scale with a growing volume of opportunities.
Key Takeaways
Intelligent Automation That Preserves Time and Workflows
-
AI-Driven Grant Parsing with Human Approval
An Azure Persistent AI Agent extracts, formats, and scores funding opportunities, while human reviewers retain final publishing authority.
-
Multi-Source Aggregation Without Custom Parsers
The system ingests JSON files, PDFs, and form submissions without the need for source-specific transformation logic.
-
From Hours to Minutes: Faster Publishing with Less Manual Work
Automating weekly grant pulls eliminated hours per person of manual aggregation per week.
-
Future-Ready Architecture Built for Expansion
New funding API sources can be integrated in days, not weeks, enabling rapid expansion across state and federal systems.
-
Structured, Searchable Data for Better Decision-Making
The AI Agent outputs standardized JSON documents which are automatically loaded into FundHubWA’s WordPress website which saves time, improves consistency and usability.

The Challenge
Manual Grant Posting Delayed Access to Critical Funding
FundHubWA, administered by the Washington State Department of Commerce, connects residents to climate and clean energy funding opportunities posted on their website. However, keeping grant listings up to date required a labor-intensive manual process. Staff had to search multiple sites, review PDFs and web pages, filter opportunities against scoring criterion, summarize content in Excel, and then upload it into WordPress.
This process took hours each week with limited staff, increasing the risk of delayed or missed funding opportunities and making it difficult to scale. Faced with the challenges of limited staffing and the end of a supporting vendor contract, Washington’s Department of Commerce needed a more efficient approach without losing the human oversight required to evaluate and publish funding opportunities.

Our Approach
Human-in-the-Loop and AI Agent Balance Workload Efficiency
To modernize FundHubWA’s process without losing human oversight, our team analyzed the existing manual workflow, reviewed and scoring criteria and translated the requirements into a structured AI instruction framework. Using Azure AI Persistent Agent tool, our team created a globally instructed agent to extract, structure, and score funding opportunities. Rather than replacing human judgment, we designed a solution with human-in-the-loop workflow.
The Solution
AI-Powered Aggregator That Automates and Standardizes Grant Publishing
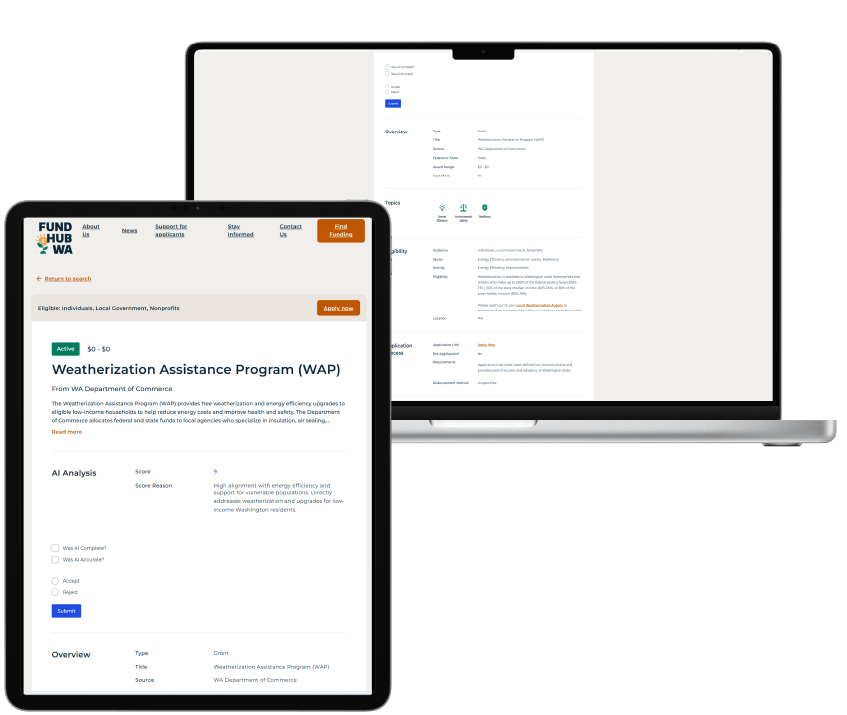
Resource Data built an AI-powered funding aggregator to automate how funding opportunities are collected, structured, and prepared for review before publishing. At the solution’s core is a custom C# orchestrator that pulls data from multiple sources, including APIs and PDFs, and sends it to the AI agent.
The AI agent performs two key functions. It uses natural language processing to extract key details and structure them into a standardized JSON schema. Each opportunity is scored against defined climate and Washington-specific criteria, producing a relevance score and explanation. It is then loaded into WordPress as a draft for human review, improving speed, consistency, and scalability while maintaining oversight.
Features
Intelligent Automation Speeds Website Publishing
-
Azure Persistent AI Agent removes manual data processing work
The AI agent automatically reads PDFs and API data, extracts relevant information, and structures it into the required format, reducing the need for staff to manually review and transcribe funding opportunities.
-
Automated multi-source API ingestion for rapid expansion
Detailed scripts supported unit, functional testing, user acceptance, and regression testing scenarios across customer and agent interactions.
-
PDF and Document Parsing for unstructured content conversion in WordPress
State agencies can upload funding documents directly, and the AI auto-fills the web forms for funding opportunities.
-
AI Scoring with Justifications support faster and informed decisions
A structured workflow allowed teams to log, prioritize, resolve, and retest issues as system configuration progressed.
-
Schema-Driven JSON Output for Clean Content Management System (CMS) Integration
Structured outputs align precisely with WordPress data requirements, eliminating manual reformatting.

- Dustin Schmidt, Technical Lead, Resource DataFundHub was an excellent application of agentic AI as it significantly aids the humans involved rather than replacing them. The FundHub AI Agent is supporting a great cause; connecting tribes, residents, and businesses in Washington to climate and clean energy funding opportunities to make Washington cleaner, healthier and more resilient.

Results
Faster Processing, Smarter Outputs, and Scalable Architecture
The AI-powered aggregator replaced hours of manual weekly work and eliminated Excel-based grant tracking. Funding opportunities are now automatically retrieved, structured, and drafted for review directly on their website, reducing delays and significantly improving efficiency from hours to minutes.
State agencies can now submit funding documents directly, increasing engagement and expand the portal’s reach. FundHubWA is now positioned as a scalable, multi-source funding intelligence platform rather than a manually curated website.

What's Next
Expanding Intelligent Automation Across State Agencies
With the architecture in place, FundHubWA is positioned to integrate additional state and federal funding APIs quickly. Future enhancements may include deeper criteria modeling, personalized funding recommendations, and expanded agency self-service submission tools.
Resource Data continues to support the Department of Commerce as it evolves FundHubWA’s services into a comprehensive, AI-assisted funding discovery platform that balances automation and human review.




Case Study FAQ
A public-sector team can use AI effectively by automating the repetitive work of gathering, extracting, organizing, and drafting funding opportunities while keeping staff in charge of final approval. That is usually the most practical model for government and quasi-public programs because it improves speed without giving up editorial control, accountability, or program judgment.
The important distinction is that AI should support the publishing workflow, not replace it. In many agencies, staff spend too much time searching websites, reviewing PDFs, summarizing opportunities, and re-entering information into spreadsheets or a CMS. That manual burden slows publishing and makes it harder to keep funding information current. A stronger model uses AI to prepare structured, review-ready drafts so staff can focus on relevance, quality, and publication decisions.
In Resource Data’s case study, FundHubWA had been relying on a labor-intensive process to search for funding opportunities, summarize them in Excel, and upload them into WordPress. Resource Data built an AI-powered funding aggregator that automated much of that work while preserving human review before publication. This Resource Data case study demonstrates that human-in-the-loop AI can reduce manual workload, improve publishing speed, and create a more scalable public-service workflow without sacrificing oversight.
It takes a workflow that connects multi-source data ingestion, AI-based extraction, structured output, and CMS-ready publishing into one coordinated system. Automating just one step is usually not enough. The process has to move from source collection all the way through web-ready formatting if the result is going to save time and actually improve publishing operations.
A public-sector funding site often has to work with mixed formats such as APIs, PDFs, and direct submissions. That means the automation layer must be able to handle both structured and unstructured content, normalize it into a consistent schema, and produce an output format that WordPress or another content management system can accept without manual rework. Human review still matters, but the underlying system should reduce the amount of routine formatting and data handling required before that review happens.
In Resource Data’s case study, the solution combined a custom C# orchestrator, Azure Persistent Agents, natural language processing, standardized JSON output, and direct drafting into WordPress. Resource Data’s example shows that automating collection, extraction, scoring, and CMS preparation creates a much stronger content operations pipeline than relying on piecemeal manual tasks. The business and operational impact is faster publishing, more consistent listings, and a platform that can scale as funding sources grow.
They struggle because manual grant publishing is a slow, fragmented workflow that depends too heavily on limited staff capacity. When people have to search multiple websites, interpret PDFs and web pages, filter opportunities against criteria, summarize findings in spreadsheets, and then upload the results into WordPress, the process becomes both time-consuming and hard to scale. Even when staff are diligent, manual work creates bottlenecks.
The bigger issue is not just labor. It is service risk. If grant and incentive listings take too long to process, the portal can miss timely opportunities, publish information more slowly than users need, or fail to keep pace with a growing volume of funding data. That can affect residents, businesses, agencies, and other stakeholders who rely on the portal for current information.
In Resource Data’s case study, FundHubWA’s staff spent hours each week on this manual workflow. The case study notes that this increased the risk of delayed or missed funding opportunities and made scaling difficult, especially with limited staffing and the end of a supporting vendor contract. This Resource Data case study demonstrates that outdated content operations are often a workflow design problem, not just a staffing problem. The operational impact of fixing that workflow is better timeliness, reduced staff burden, and more reliable access to public funding information.
An AI-powered funding aggregator helps by replacing disconnected manual tracking tasks with a system that automatically retrieves, structures, scores, and prepares funding opportunities for publication. Instead of relying on spreadsheets as a temporary content-processing tool, the organization gets a repeatable digital workflow that can support higher volume, better consistency, and faster publication.
That shift matters because Excel-based tracking usually reflects a process where staff are doing too much interpretive and clerical work by hand. As volume grows, spreadsheet workflows become harder to maintain and more likely to slow down publication or introduce inconsistency. A funding intelligence platform, by contrast, treats funding opportunities as structured data that can be processed, searched, reviewed, and published more efficiently.
In Resource Data’s case study, FundHubWA moved away from Excel-based grant tracking after Resource Data built an AI-powered funding aggregator that automatically retrieved opportunities, structured them, and drafted them directly on the website for human review. The results section says the platform shifted from a manually curated website to a scalable, multi-source funding intelligence platform. This Resource Data case study demonstrates that the value of automation is not just time savings. It is the creation of a more scalable operating model that improves consistency, reduces manual handling, and better supports future growth.
Human-in-the-loop review plays the role of final judgment, quality control, and publishing authority. In a public-sector funding workflow, AI can handle the repetitive tasks of extracting information, organizing it into a structured format, and scoring it against defined criteria, but staff still need to decide what gets published. That balance is important because funding opportunities often require contextual interpretation and accountability that should not be delegated entirely to automation.
A strong human-in-the-loop model preserves trust while still capturing efficiency gains. Reviewers are no longer spending most of their time hunting for information or retyping it into web forms. Instead, they are reviewing AI-prepared drafts, checking the relevance score and explanation, and making the final decision about whether the opportunity should be published.
In Resource Data’s case study, the Azure Persistent AI Agent extracted, formatted, and scored opportunities, but human reviewers retained final publishing authority. Resource Data explicitly designed the solution to modernize the workflow without losing human oversight. This Resource Data case study demonstrates that human-in-the-loop automation is often the right public-sector pattern because it improves speed and consistency while preserving governance, editorial control, and decision quality. The business and operational impact is better staff leverage without sacrificing accountability.
It can do that by combining an orchestration layer with an AI-based extraction layer that is designed to work across multiple source formats instead of relying only on source-specific transformation logic. Traditional parser-heavy approaches can become expensive and slow to maintain because every new source may require custom development. A more flexible architecture uses AI to interpret content from different formats and then map it into a standard schema.
That approach is especially useful for funding portals because opportunity data often comes from a mix of structured APIs, semi-structured forms, and unstructured documents such as PDFs. If the system can normalize those inputs into a single schema, the downstream publishing workflow becomes much more manageable. The CMS receives consistent fields even when the original sources vary widely.
In Resource Data’s case study, one of the stated takeaways is that the system ingests JSON files, PDFs, and form submissions without requiring source-specific transformation logic. Resource Data also describes a custom C# orchestrator that pulls data from multiple sources and sends it to the AI agent for extraction and structuring. This Resource Data case study demonstrates that multi-source ingestion without custom parsers for every source can reduce integration effort, shorten onboarding time for new sources, and improve scalability as more state and federal funding systems are added.
AI scoring helps by giving staff a first-pass relevance assessment based on defined criteria, while structured justifications explain why an opportunity appears to fit. That combination does not replace judgment, but it makes the review process more efficient because staff start with a draft that already includes both the extracted details and a rationale for relevance. Instead of evaluating every source from scratch, reviewers can focus on confirming or refining the recommendation.
This matters most in high-volume or resource-constrained environments. When staff are processing many opportunities across different funding programs, a relevance score and explanation can speed triage, improve consistency, and help teams prioritize their attention. It creates a more disciplined review process than simply scanning raw documents and making ad hoc decisions.
In Resource Data’s case study, each opportunity was scored against defined climate and Washington-specific criteria, producing both a relevance score and an explanation before the item was loaded into WordPress as a draft. Resource Data’s example shows that structured scoring supports better decision-making because it makes the AI’s reasoning more usable in a real workflow. The operational impact is faster review, more consistent publishing standards, and better use of limited staff time across a growing opportunity pipeline.
The operational benefit is that schema-driven JSON turns messy, mixed-format funding content into clean, predictable website data. When outputs are standardized before they reach WordPress, staff do not have to spend time manually reformatting content to fit the CMS. That reduces friction in the publishing process and makes the system easier to maintain as volume grows.
A structured schema also improves consistency across listings. If each funding opportunity is mapped into the same fields and content pattern, the site becomes easier to search, review, and manage. That matters for both internal operations and user experience. Consistent structured content is easier for staff to edit and easier for the public to navigate.
In Resource Data’s case study, the AI agent outputs standardized JSON documents that are automatically loaded into FundHubWA’s WordPress website. The case study also notes that the structured outputs align precisely with WordPress data requirements, eliminating manual reformatting. This Resource Data case study demonstrates that schema-driven output is not just a technical preference. It is a content operations advantage that saves time, improves consistency, and creates a stronger foundation for scalable digital publishing.
Faster integration matters because a funding platform becomes more valuable as it can cover more relevant sources without long implementation delays. If every new API takes weeks of custom work, expansion slows down and the portal may miss opportunities to surface timely funding information from additional state or federal systems. A faster integration model lets the program respond more quickly as new sources become available.
This is especially important for climate and clean energy funding, where the opportunity landscape can change across agencies, programs, and policy cycles. A platform that can add sources in days rather than weeks is better positioned to keep listings current, broaden its coverage, and serve more users without scaling staff effort at the same rate.
In Resource Data’s case study, one of the key takeaways is that new funding API sources can be integrated in days, not weeks, because of the architecture Resource Data built. The results and future sections also describe FundHubWA as a scalable, multi-source funding intelligence platform positioned to expand across additional state and federal funding APIs. This Resource Data case study demonstrates that integration speed is a growth enabler. The business and operational impact is faster expansion, better responsiveness to new funding streams, and improved scalability without proportional increases in manual work or development overhead.
A public-sector funding portal can do that by automating repetitive content-processing tasks while reserving final judgment for the people who understand the program’s mission, criteria, and audience. The smartest use of AI in this context is not full replacement. It is workforce amplification. The system handles retrieval, extraction, structuring, and draft creation, and staff handle review, oversight, and publication decisions. That model improves service quality because it reduces the time staff spend on low-value clerical work and gives them more time to evaluate whether opportunities actually fit the program’s goals. It also improves publishing speed because the content arrives in a more review-ready format instead of requiring manual assembly from scattered sources.
In Resource Data’s case study, the AI-powered funding aggregator shifted FundHubWA’s team from manual weekly processing to decision-making and review. The results say the platform reduced publishing time from hours to minutes while preserving human approval authority. This Resource Data case study demonstrates that public-sector automation can raise service levels without weakening oversight. The business and operational impact is faster time-to-publish, more sustainable staffing, higher consistency, and a stronger ability to scale funding discovery services as demand grows.